Descripcion general
Muchas organizaciones publican indicadores estadisticos derivados de encuestas (tasas de desempleo, pobreza, innovacion) sin mostrar como fueron calculados. El numero final es publico, pero la metodologia – que variables se usaron, que transformaciones se aplicaron, que diseno muestral se uso – queda oculta.
metasurvey resuelve esto separando los datos privados de la metodologia publica. Se despliega la API de metasurvey en tu propia infraestructura donde:
- Los microdatos son privados: los archivos de la encuesta nunca salen de tu red.
- Los indicadores son publicos: los resultados (estimaciones puntuales, errores estandar, intervalos de confianza) se sirven via la API.
- La metodologia es transparente: cualquiera puede consultar la receta (pasos de transformacion) y el workflow (llamadas de estimacion y diseno muestral) que produjo cada indicador.
La cadena de trazabilidad es:
Indicador Workflow Receta
(el numero) --> (como se estimo) --> (como se construyeron las variables)
value: 0.082 svymean(~pd, design) step_compute(svy, pd = ...)
se: 0.003 estimation_type: annual step_recode(svy, pea, ...)
cv: 0.037 recipe_ids: [ech_emp_001] depends_on: [e27, f66, ...]Arquitectura
El sistema tiene dos servicios R: una API publica que sirve indicadores y su trazabilidad, y un Worker privado que tiene metasurvey instalado y acceso a los microdatos. El worker es el unico componente que toca los datos crudos de la encuesta.
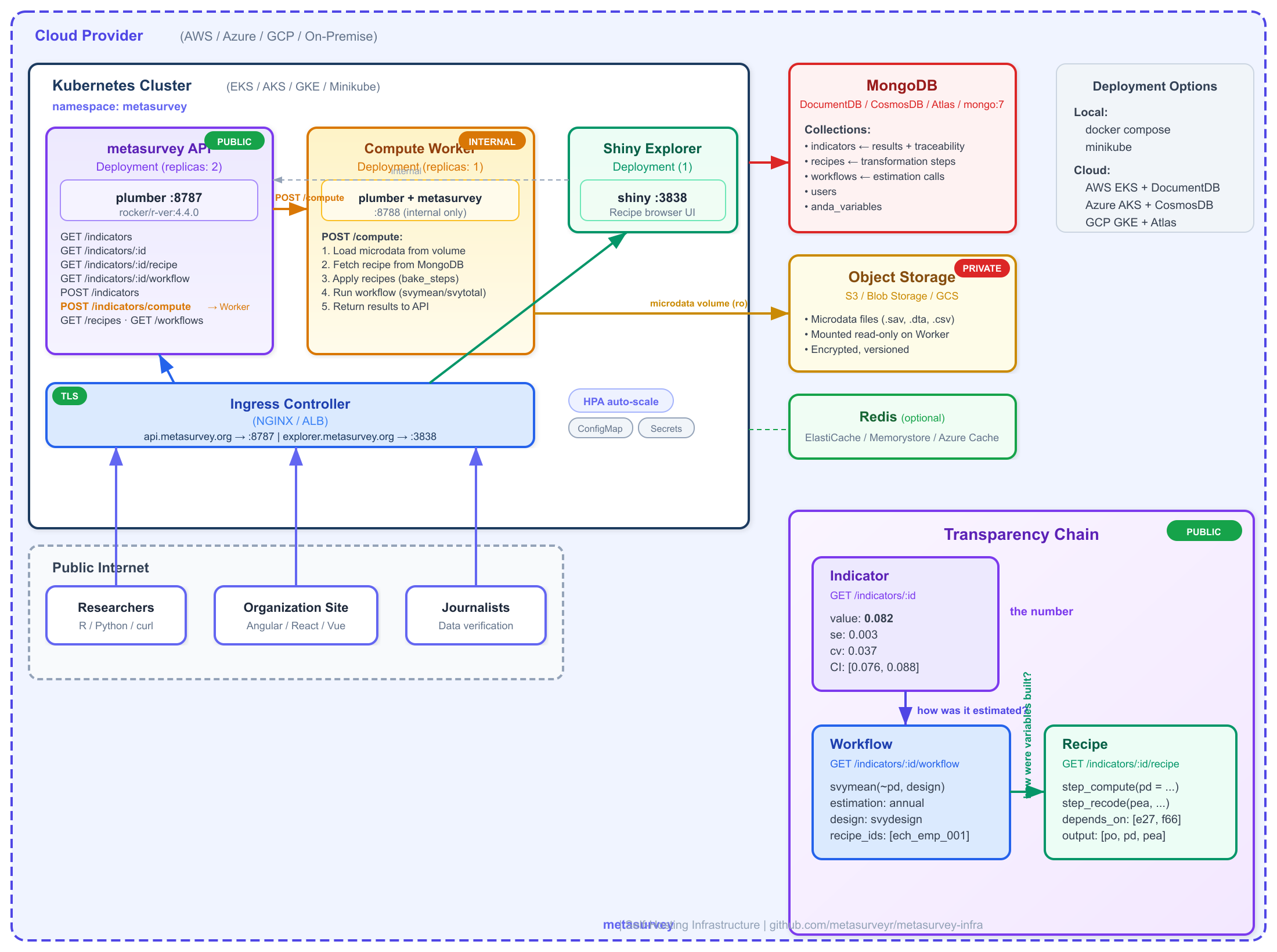
Infraestructura de self-hosting de metasurvey
Separacion clave: El Worker carga los microdatos,
busca las recetas en MongoDB, las aplica (bake_steps),
ejecuta la estimacion (workflow), y publica el resultado en
la API. La API publica nunca toca los microdatos – solo sirve
indicadores pre-computados y su trazabilidad.
El frontend tambien puede solicitar estimaciones bajo
demanda con filtros (ej., “tasa de desempleo para mujeres en
Montevideo”) via POST /indicators/compute, que la API
delega al Worker.
Inicio rapido con Docker Compose
El repositorio incluye un docker-compose.yml que levanta
MongoDB, la API plumber y el explorador Shiny de recetas. No se necesita
base de datos externa.
2. Levantar el stack
Esto inicia cuatro servicios:
| Servicio | URL | Descripcion |
|---|---|---|
mongo |
localhost:27017 |
MongoDB 7 con volumen persistente |
worker |
localhost:8788 |
Worker de computo (solo interno) |
api |
http://localhost:8787 |
API REST plumber |
shiny |
http://localhost:3838 |
Explorador de recetas |
3. Inicializar la base de datos
# Crear colecciones e indices
docker compose exec mongo mongosh \
-u metasurvey -p cambiar-en-produccion \
--authenticationDatabase admin \
metasurvey /dev/stdin < inst/scripts/setup_mongodb.js
# Cargar recetas, workflows e indicadores de ejemplo
docker compose exec api Rscript -e '
Sys.setenv(
METASURVEY_MONGO_URI = "mongodb://metasurvey:cambiar-en-produccion@mongo:27017/?authSource=admin"
)
source("/app/seed_ech_recipes.R")
'Calcular y publicar indicadores
El flujo tipico: cargar datos de la encuesta, aplicar una receta, ejecutar un workflow y publicar el resultado como indicador con trazabilidad completa.
library(metasurvey)
# 1. Cargar datos de la encuesta (privado -- se queda en tu servidor)
svy <- Survey$new(
data = my_survey_data,
edition = "2024",
type = "ech",
engine = "data.table",
weight = add_weight(annual = "W_ANO")
)
# 2. Aplicar una receta (define variables como estado de desempleo)
svy <- step_compute(svy,
pd = data.table::fcase(
pobpcoac == 2, 1L,
pobpcoac %in% c(1, 3), 0L
),
comment = "Desocupado: POBPCOAC == 2"
)
svy <- bake_steps(svy)
# 3. Ejecutar la estimacion (workflow)
result <- workflow(
svy = list(svy),
survey::svymean(~pd, na.rm = TRUE),
estimation_type = "annual"
)
# result es un data.table:
# stat value se cv
# svymean: pd 0.082 0.003 0.037Publicar el indicador en la API:
# Conectar a la API local
configure_api("http://localhost:8787")
api_login("admin@example.com", "tu-password")
# Construir el payload del indicador
indicator <- list(
name = "Tasa de desempleo 2024",
description = "Tasa de desempleo anual, poblacion de 14 y mas",
recipe_id = "ech_employment_001",
workflow_id = "ech_wf_labor",
survey_type = "ech",
edition = "2024",
estimation_type = "annual",
stat = result$stat[1],
value = result$value[1],
se = result$se[1],
cv = result$cv[1],
confint_lower = result$confint_lower[1],
confint_upper = result$confint_upper[1],
metadata = list(
formula = "~pd",
estimation_function = "svymean"
)
)
# Publicar (requiere autenticacion)
resp <- httr2::request("http://localhost:8787/indicators") |>
httr2::req_headers(
Authorization = paste("Bearer", Sys.getenv("METASURVEY_TOKEN"))
) |>
httr2::req_body_json(indicator) |>
httr2::req_perform()
httr2::resp_body_json(resp)
# {ok: true, id: "ind_1708099200_42"}Consumir indicadores (transparencia)
Una vez publicados, los indicadores y su metodologia completa son accesibles sin autenticacion. Esta es la capa de transparencia.
Obtener el workflow (como se estimo)
{
"ok": true,
"indicator_id": "ind_ech_unemployment_2024",
"workflow": {
"id": "ech_wf_labor",
"name": "Mercado Laboral ECH",
"estimation_type": "annual",
"recipe_ids": ["ech_pobpcoac_000", "ech_employment_001"],
"calls": [
"svymean(~pea, design, na.rm=TRUE)",
"svymean(~po, design, na.rm=TRUE)",
"svymean(~pd, design, na.rm=TRUE)"
],
"call_metadata": [
{
"type": "svymean",
"formula": "~pea",
"description": "Tasa de actividad"
},
{
"type": "svymean",
"formula": "~pd",
"description": "Tasa de desempleo"
}
]
}
}El workflow indica que funcion estadistica se uso
(svymean), que formula (~pd),
y que recetas se aplicaron a los datos antes de la
estimacion.
Obtener la receta (como se construyeron las variables)
{
"ok": true,
"indicator_id": "ind_ech_unemployment_2024",
"recipe": {
"id": "ech_employment_001",
"name": "Employment Status",
"steps": [
"step_compute(svy, po = fcase(pobpcoac == 1, 1L, TRUE, 0L), comment = 'Employed')",
"step_compute(svy, pd = fcase(pobpcoac == 2, 1L, TRUE, 0L), comment = 'Unemployed')",
"step_compute(svy, pea = fcase(pobpcoac %in% 1:2, 1L, TRUE, 0L), comment = 'EAP')"
],
"depends_on": ["pobpcoac"],
"doc": {
"input_variables": ["pobpcoac"],
"output_variables": ["po", "pd", "pea"],
"pipeline": [
{"step": 1, "type": "compute", "outputs": ["po"]},
{"step": 2, "type": "compute", "outputs": ["pd"]},
{"step": 3, "type": "compute", "outputs": ["pea"]}
]
}
}
}La receta muestra exactamente como se construyo cada variable a partir de las variables originales de la encuesta. Combinada con el workflow, cualquiera puede verificar la cadena completa de calculo sin acceder a los microdatos.
Referencia de la API de indicadores
| Metodo | Endpoint | Auth | Descripcion |
|---|---|---|---|
GET |
/indicators |
No | Listar y buscar indicadores publicados |
GET |
/indicators/:id |
No | Obtener un indicador con metadatos |
GET |
/indicators/:id/recipe |
No | Obtener la receta que construyo las variables |
GET |
/indicators/:id/workflow |
No | Obtener el workflow (estimacion + diseno) |
POST |
/indicators |
Si | Publicar un indicador computado |
POST |
/indicators/compute |
Si | Estimar bajo demanda via el Worker (con filtros) |
Parametros de consulta para GET /indicators
| Parametro | Tipo | Descripcion |
|---|---|---|
search |
string | Busqueda regex sobre el nombre del indicador |
survey_type |
string | Filtrar por tipo de encuesta |
recipe_id |
string | Filtrar por ID de receta |
workflow_id |
string | Filtrar por ID de workflow |
edition |
string | Filtrar por edicion de la encuesta |
limit |
integer | Resultados maximos (por defecto 50) |
offset |
integer | Omitir N resultados (por defecto 0) |
Campos del documento indicador
| Campo | Tipo | Requerido | Descripcion |
|---|---|---|---|
id |
string | Auto | Identificador unico |
name |
string | Si | Nombre del indicador |
workflow_id |
string | Si | Workflow que lo produjo |
value |
number | Si | Estimacion puntual |
recipe_id |
string | No | Receta que construyo las variables |
description |
string | No | Descripcion legible |
survey_type |
string | No | Tipo de encuesta |
edition |
string | No | Edicion de la encuesta |
estimation_type |
string | No |
annual, quarterly,
monthly
|
stat |
string | No | Etiqueta del estadistico (ej., svymean: pd) |
se |
number | No | Error estandar |
cv |
number | No | Coeficiente de variacion |
confint_lower |
number | No | Limite inferior del intervalo de confianza |
confint_upper |
number | No | Limite superior del intervalo de confianza |
metadata |
object | No | Contexto adicional (formula, notas) |
published_at |
string | Auto | Marca de tiempo ISO |
Despliegue con Minikube
Para despliegue local basado en Kubernetes, se puede usar Minikube.
Deployment de MongoDB
# k8s/mongo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metasurvey-mongo
namespace: metasurvey
spec:
replicas: 1
selector:
matchLabels:
app: metasurvey-mongo
template:
metadata:
labels:
app: metasurvey-mongo
spec:
containers:
- name: mongo
image: mongo:7
ports:
- containerPort: 27017
env:
- name: MONGO_INITDB_ROOT_USERNAME
value: metasurvey
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: mongo-password
---
apiVersion: v1
kind: Service
metadata:
name: mongo-service
namespace: metasurvey
spec:
selector:
app: metasurvey-mongo
ports:
- port: 27017
targetPort: 27017Deployment del Worker
# k8s/worker.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metasurvey-worker
namespace: metasurvey
spec:
replicas: 1
selector:
matchLabels:
app: metasurvey-worker
template:
metadata:
labels:
app: metasurvey-worker
spec:
containers:
- name: worker
image: ghcr.io/metasurveyr/metasurvey-worker:latest
ports:
- containerPort: 8788
env:
- name: METASURVEY_MONGO_URI
value: "mongodb://metasurvey:$(MONGO_PASSWORD)@mongo-service:27017/?authSource=admin"
- name: MONGO_PASSWORD
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: mongo-password
volumeMounts:
- name: survey-data
mountPath: /data/surveys
readOnly: true
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "4Gi"
cpu: "2000m"
volumes:
- name: survey-data
persistentVolumeClaim:
claimName: survey-microdata-pvc
---
apiVersion: v1
kind: Service
metadata:
name: worker-service
namespace: metasurvey
spec:
selector:
app: metasurvey-worker
ports:
- port: 8788
targetPort: 8788Deployment de la API
# k8s/api.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metasurvey-api
namespace: metasurvey
spec:
replicas: 2
selector:
matchLabels:
app: metasurvey-api
template:
metadata:
labels:
app: metasurvey-api
spec:
containers:
- name: api
image: ghcr.io/metasurveyr/metasurvey-api:latest
ports:
- containerPort: 8787
env:
- name: METASURVEY_MONGO_URI
value: "mongodb://metasurvey:$(MONGO_PASSWORD)@mongo-service:27017/?authSource=admin"
- name: MONGO_PASSWORD
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: mongo-password
- name: METASURVEY_JWT_SECRET
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: jwt-secret
- name: METASURVEY_WORKER_URL
value: "http://worker-service:8788"
livenessProbe:
httpGet:
path: /health
port: 8787
initialDelaySeconds: 30
readinessProbe:
httpGet:
path: /health
port: 8787
initialDelaySeconds: 10
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
---
apiVersion: v1
kind: Service
metadata:
name: metasurvey-api
namespace: metasurvey
spec:
type: NodePort
selector:
app: metasurvey-api
ports:
- port: 8787
targetPort: 8787Aplicar y probar
kubectl create namespace metasurvey
kubectl create secret generic metasurvey-secrets \
--namespace metasurvey \
--from-literal=mongo-password=cambiar \
--from-literal=jwt-secret=cambiar
kubectl apply -f k8s/mongo.yaml -f k8s/worker.yaml -f k8s/api.yaml
# Acceder a la API
minikube service metasurvey-api -n metasurveyDespliegue en AWS (EKS)
Para produccion en AWS se usa EKS con DocumentDB (MongoDB compatible) como base de datos gestionada.
2. Crear DocumentDB (MongoDB compatible)
aws docdb create-db-cluster \
--db-cluster-identifier metasurvey-db \
--engine docdb \
--master-username metasurvey_admin \
--master-user-password "$DB_PASSWORD" \
--vpc-security-group-ids "$SG_ID" \
--db-subnet-group-name "$SUBNET_GROUP"
aws docdb create-db-instance \
--db-instance-identifier metasurvey-db-1 \
--db-cluster-identifier metasurvey-db \
--db-instance-class db.r6g.large \
--engine docdb3. Configurar secrets en Kubernetes
aws eks update-kubeconfig --name metasurvey-prod --region sa-east-1
kubectl create namespace metasurvey
kubectl create secret generic metasurvey-secrets \
--namespace metasurvey \
--from-literal=mongo-uri="mongodb://metasurvey_admin:$DB_PASSWORD@metasurvey-db.cluster-xxx.sa-east-1.docdb.amazonaws.com:27017/?tls=true&tlsCAFile=/rds-combined-ca-bundle.pem&retryWrites=false" \
--from-literal=jwt-secret="$(openssl rand -hex 32)"4. Deployment con ALB Ingress
# k8s/aws-api.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metasurvey-api
namespace: metasurvey
spec:
replicas: 2
selector:
matchLabels:
app: metasurvey-api
template:
metadata:
labels:
app: metasurvey-api
spec:
containers:
- name: api
image: ghcr.io/metasurveyr/metasurvey-api:latest
ports:
- containerPort: 8787
env:
- name: METASURVEY_MONGO_URI
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: mongo-uri
- name: METASURVEY_JWT_SECRET
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: jwt-secret
- name: METASURVEY_WORKER_URL
value: "http://worker-service:8788"
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8787
initialDelaySeconds: 30
readinessProbe:
httpGet:
path: /health
port: 8787
initialDelaySeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: metasurvey-api
namespace: metasurvey
spec:
type: ClusterIP
selector:
app: metasurvey-api
ports:
- port: 8787
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: metasurvey-ingress
namespace: metasurvey
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/certificate-arn: "$ACM_CERT_ARN"
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
spec:
rules:
- host: api.metasurvey.ejemplo.org
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: metasurvey-api
port:
number: 8787Despliegue en Azure (AKS)
Para produccion en Azure se usa AKS con CosmosDB (API MongoDB) como base de datos gestionada.
2. Crear CosmosDB con API MongoDB
az cosmosdb create \
--name cosmos-metasurvey \
--resource-group rg-metasurvey \
--kind MongoDB \
--capabilities EnableMongo \
--default-consistency-level Session \
--locations regionName=brazilsouth
# Obtener connection string
COSMOS_URI=$(az cosmosdb keys list \
--name cosmos-metasurvey \
--resource-group rg-metasurvey \
--type connection-strings \
--query "connectionStrings[0].connectionString" -o tsv)4. Deployment con NGINX Ingress
# k8s/azure-api.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metasurvey-api
namespace: metasurvey
spec:
replicas: 2
selector:
matchLabels:
app: metasurvey-api
template:
metadata:
labels:
app: metasurvey-api
spec:
containers:
- name: api
image: ghcr.io/metasurveyr/metasurvey-api:latest
ports:
- containerPort: 8787
env:
- name: METASURVEY_MONGO_URI
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: mongo-uri
- name: METASURVEY_JWT_SECRET
valueFrom:
secretKeyRef:
name: metasurvey-secrets
key: jwt-secret
- name: METASURVEY_WORKER_URL
value: "http://worker-service:8788"
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8787
initialDelaySeconds: 30
readinessProbe:
httpGet:
path: /health
port: 8787
initialDelaySeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: metasurvey-api
namespace: metasurvey
spec:
type: ClusterIP
selector:
app: metasurvey-api
ports:
- port: 8787
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: metasurvey-ingress
namespace: metasurvey
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
nginx.ingress.kubernetes.io/ssl-redirect: "true"
spec:
ingressClassName: nginx
tls:
- hosts:
- api.metasurvey.ejemplo.org
secretName: metasurvey-tls
rules:
- host: api.metasurvey.ejemplo.org
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: metasurvey-api
port:
number: 8787# Instalar NGINX Ingress Controller
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx --create-namespace
# Instalar cert-manager para TLS
helm repo add jetstack https://charts.jetstack.io
helm install cert-manager jetstack/cert-manager \
--namespace cert-manager --create-namespace \
--set crds.enabled=true
kubectl apply -f k8s/azure-api.yamlFeature Flags
La API soporta variables de entorno para controlar que modulos estan disponibles. Esto permite usar la misma imagen en diferentes configuraciones:
| Variable | Default | Descripcion |
|---|---|---|
METASURVEY_ENABLE_INDICATORS |
1 |
Habilitar endpoints /indicators
|
METASURVEY_ENABLE_WORKER |
0 |
Habilitar POST /indicators/compute (bajo demanda) |
Por ejemplo, la API publica de metasurvey en Railway solo sirve recetas y workflows – indicadores y worker estan deshabilitados:
Un despliegue self-hosted con todas las capacidades:
Despliegue hibrido: Registro publico + Infraestructura privada
No necesitas correr tu propio MongoDB para acceder a las recetas compartidas. Podes desplegar tu propia API + Worker apuntando al registro publico de recetas de metasurvey, para que investigadores con acceso a microdatos apliquen recetas publicadas por la comunidad.
La organizacion despliega dos servicios:
-
plumber API (
:8787) – se conecta al MongoDB publico para leer recetas y workflows. Recibe requests del frontend o investigadores, y delega las estimaciones al worker. -
Worker (
:8788) – tiene metasurvey instalado y acceso a los microdatos privados. Obtiene las recetas del registro publico (via MongoDB), las aplica, y ejecuta las estimaciones.
MongoDB publico de metasurvey Tu infraestructura
(recetas, workflows) (red privada)
+-------------------+ +---------------------------+
| MongoDB Atlas |<----------| plumber API :8787 |
| (solo lectura) | | - lee recetas/wf |
+-------------------+ | - proxie POST /compute |
+-------------+-------------+
|
POST /compute|
v
+-------------+-------------+
| Worker :8788 |
| - carga microdatos |
| - aplica recetas |
| - ejecuta workflow() |
+---------------------------+
^
+-------------+-------------+
| Microdatos (.sav, .dta) |
| PRIVADOS — nunca salen |
+---------------------------+# .env para despliegue hibrido
# Ambos (API y Worker) apuntan al MongoDB publico de metasurvey
METASURVEY_MONGO_URI=mongodb+srv://readonly:public@metasurvey.mongodb.net
METASURVEY_DB=metasurvey
# El worker tiene microdatos locales
SURVEY_DATA_PATH=/secure/microdatos
# La API delega estimaciones al worker
METASURVEY_WORKER_URL=http://worker:8788
METASURVEY_ENABLE_WORKER=1
# Indicadores deshabilitados (no hay MongoDB local para guardarlos)
METASURVEY_ENABLE_INDICATORS=0En este modo:
- Recetas y workflows se obtienen del registro publico – cualquier receta publicada por la comunidad esta disponible para tu API y worker.
- Los microdatos son privados – el worker carga archivos de encuesta desde un volumen local, nunca expuestos externamente.
-
La estimacion es local – la API recibe el request,
lo delega al worker, que aplica las recetas y ejecuta
workflow()en tu infraestructura. - Sin MongoDB propio – usas el registro publico tal cual.
Esto es util para equipos de investigacion que tienen acceso a microdatos restringidos y quieren aplicar recetas estandarizadas sin mantener su propia base de datos.
Despliegue en produccion
Para despliegues de produccion con modulos Terraform (AWS/Azure/GCP), Helm charts y pipelines CI/CD, ver el repositorio de infraestructura:
El repositorio de infraestructura incluira:
- Modulos Terraform para bases de datos gestionadas (RDS, DocumentDB/CosmosDB, Cloud SQL, Memorystore)
- Manifiestos Kubernetes con autoescalado, ingress TLS y gestion de secretos
- Builds de imagenes Docker y configuracion de registry
- Monitoreo y health checks
Proximos pasos
- Referencia de la API y Base de Datos – Documentacion completa de endpoints, esquema MongoDB y autenticacion
- Creacion y publicacion de recetas – Construir recetas para procesamiento reproducible de encuestas
-
Workflows de
estimacion – Calcular estimaciones ponderadas de encuestas
con
workflow()